

By default, data inside a container is lost when the container no longer exists, and it becomes hard to access that data if other processes need it.
Docker gives two ways to store container data on the host machine, so that it is persisted even after the container stops: volumes and bind mounts.
Docker also allows storing data in memory on the host machine, but this data won’t be persisted.
In this blog post, we will try to understand persisting data using volumes.
What are Volumes
Volumes are the preferred mechanism for persisting data generated by and used by Docker containers.
Volumes are not tied to the lifecycle of any container. You can delete a container that’s using a volume, and the volume won’t be deleted.
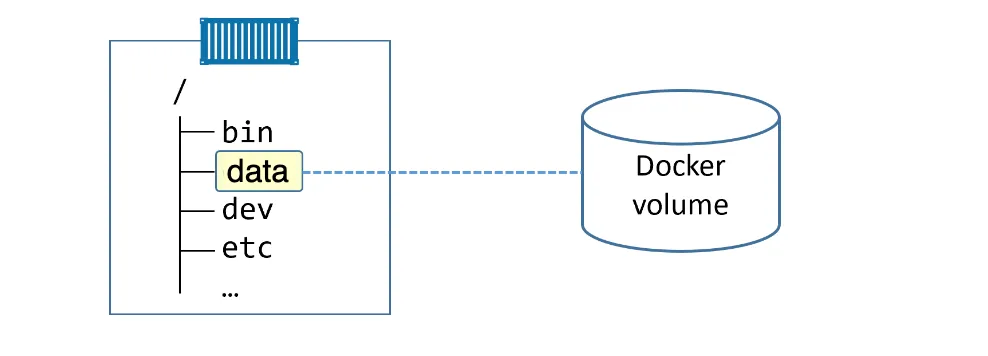
The figure below shows a Docker volume existing outside of the container as a separate object. It is mounted into the container’s filesystem at /data, and any data written to the /data directory will be stored on the volume and will exist after the container is deleted.
How to create Volumes
Volumes link a directory inside the container to a persistent storage managed by drivers, depending on the hosting service (like Azure File Storage or Amazon S3). On Docker Desktop, you can map volumes directly to host directories using the -v option in the docker run command.
For example, running a MySQL database without a volume:
docker run -d mysql:5.7
This configuration will lose any data if the container restarts. To prevent this, mount a volume:
docker run -v /your/dir:/var/lib/mysql -d mysql:5.7
This setup ensures data written to /var/lib/mysql inside the container is saved to /your/dir on your host, preserving the data through restarts. It creates a bridge between the host and the container.